

























Connected autonomous vehicles are big data marvels. They use a variety of sensors—RADAR, LIDAR, cameras, motion, ultrasonic, and more—to generate real-time data about car system performance and surroundings. That data then is interpreted almost instantly by artificial intelligence (AI) and machine learning (ML) models within car controllers. As a result, vehicles are able to safely power operations and adapt swiftly to changing internal and external conditions.
As they navigate city streets and highways, connected autonomous vehicles create around 25GB per hour from sensors and record 300TB per year in information, which is stored in data centres or the cloud [1]. This data could be leveraged to train algorithms to make transportation safer and even more enjoyable.
However, this vision has not yet been achieved, as manufacturers are encountering regulatory issues along with big data management challenges. Security and administrative standard bodies such as MIT Media Labs, Alan Turing Institute, Ethics of AI Lab and others are scrutinising the AI and ML models used to perform calculations and simulations. These organisations are concerned about a wide variety of issues, including data security and privacy, the ability of algorithms to comply with local traffic laws, and the legal implications of determining fault when accidents occur.
Automobile manufacturers also must evolve their strategies and practices to manage large data sets effectively [2]. AI models are developed and maintained according to pre-set data strategies and frameworks. Data frameworks also require data fabrics to integrate data pipelines for AI models and ensure that they are bound by key rules to drive desired business outcomes. These requirements in turn create a need for a data lake that supports data storage, processing, filtering, gateways and movement for use in different car systems. As a result, the data lake should be agile, flexible, and easy to manipulate with plug-and-play data bricks that enable simple orchestrations.
Beyond autonomous vehicles, AI models are also powering robots and automated services, used by smart cities, factories, and transportation. They’re making systems smarter, faster, and more responsive while helping to conserve precious resources such as energy and water. As a result, the time is now for organisations to create AI models that are grounded in well-designed data fabric, frameworks, and strategies.
Well-trained AI models can perform the following types of reasoning:
- Deductive – Using facts and knowledge to drive to logical conclusions, as with supervised deep learning.
- Inductive – Generalizing outcomes from specific content.
- Common sense – Learning from experiences, as with general AI.
- Monotonic – Strengthening hypotheses, using known facts and knowledge.
- Non-monotonic – Arriving at uncertain outcomes due to incomplete data, as with unsupervised learning.
- Abductive – Achieving incomplete to complete outcomes, as with semi-supervised learning.
Creating an Effective AI Model with Proper Planning and the Kanban Framework
Training AI models requires precision and process, to avoid potential disasters and unwanted behaviours [3]. You must also determine which type of AI model you wish to develop: model-centric, data-centric, or subject-centric. A model-centric version focuses on collecting vast data volumes and tuning the AI model to filter out noise [4]. A data-centric version focuses on improving data quality first, before feeding it into an open-source AI model. And a subject-centric version creates a dynamic reality where the machine is aware of its actions [5].
After deciding on the approach, you can use Kanban, a popular framework used for Agile and DevOps software development, to prepare data and build the AI mode. This process is depicted and described below.
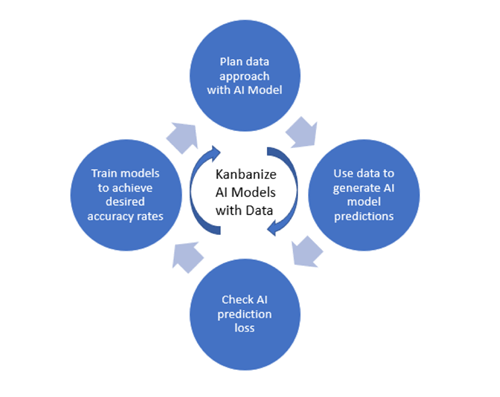
Step 1:
Plan your data approach for the AI model. Decide whether your team is going to focus on collecting data and filtering noise or preparing high quality data for use with the AI model. This is one of the most important decisions you’ll make, so take time to understand your goals, budget, technical competency of team members, and desired outcomes and then map them against AI models to choose the right one.
Step 2:
Use data to generate AI model predictions. Once you’ve built your model, you’ll want to test it with the data you’ve assembled, to determine how accurate the results are. AI models require different levels of precision based on the application. The models used for autonomous vehicles, for example, require highly sophisticated models that can interpret data with pinpoint accuracy.
Step 3: Check AI model prediction loss.
It’s comparatively easy to determine prediction loss. Simply divide the correct number of predictions by the total number of predictions. Then compare this figure against your desired accuracy rate.
Step 4: Train models to achieve desired accuracy rates.
Next, train, validate, and test AI models to ensure they can make accurate decisions based on unstructured data. This is an ongoing process that can take days or months.
Using the PCDA Method to Improve Outcomes
There are many ways to prepare AI models. We favour PDCA (Plan-Do-Check-Act), an iterative design and management method that enables continuous improvement within business controls.
Using a structured process for driving change helps keep the focus on business outcomes, including improving profitability for AI initiatives. PDCA helps teams avoid underfitting or overfitting models and hyperparameters each iteration or epoch. In addition, they can save data from each test to baseline results and adjust learning rates to improve outcomes. Finally, AI model outcomes can be reused to improve other algorithms, via transfer or federated learning.
Such process-driven AI models are used pervasively across industry applications, including:
Education – AI can be used to deliver individualized instruction in training, provide universal access to curriculum, and automate administrative tasks. By using our Kanban- and PDCA-driven approach, education organizations can reduce costs, while achieving predictable outcomes.
Energy – AI models can be used to predict demand pattern and water changes and equipment failures and identify sources of waste. Using our approach, organizations can reduce use of fossil fuels, incorporate renewable energy sources, and avoid unplanned outages.
Entertainment – AI models can predict with ever-greater accuracy what consumers want to watch and spend their money on. Our approach can help entertainment companies align their content development and marketing investments for greater return.
Medical research – AI-based models can improve drug discovery and development, population planning, and more. Using our approach can speed up processes and reduce costs, a boon in an industry where being first-to-market with new drugs and therapies typically means achieving outsized gains.
Professional sports – AI models can be used by recruiters to evaluate potential player risks and performance, enabling them to select the right talent. AI can also drive training programs, player tracking on the field, and more. Using our approach enables teams to make data-driven decisions and escalate within set controls.
Conclusion
AI adoption is growing, yet many organizations struggle to make their investments profitable. The path forward to driving higher ROI is to use disciplined processes and the right tools. FPT can help your team improve its processes, from creating high-quality data, to developing and training algorithms, by using proper planning, the Kanban framework, and PDCA approach.



