

























Introduction
Recently, Aspect based in opinion mining is the field that is very interested in Text Mining and Natural Language Processing. With the development of the Internet, Social networks, Forum, e-commerce websites, etc. expressing and sharing your opinion, news are exploding. Because the content on the Internet is increasing rapidly in the form of reviews, comments, blogs, status, tweets, etc., analyzing and classifying their aspects is essential so we need a system to classify it. Nowadays, most online social reviews include many topics in it, aspect extraction helps us better understand the document. This is a challenge because users often use very different words to express the same topic or even try to hide the topic of the question.
How to approach to text classification
There are many techniques used to extract aspects of document on social networks. But I will introduce the approach steps to solve the problem based on two typical extraction methods: BoW and TF-IDF along with typical learning algorithms such as Naïve Bayes, Support Vector Machine, Random Forest.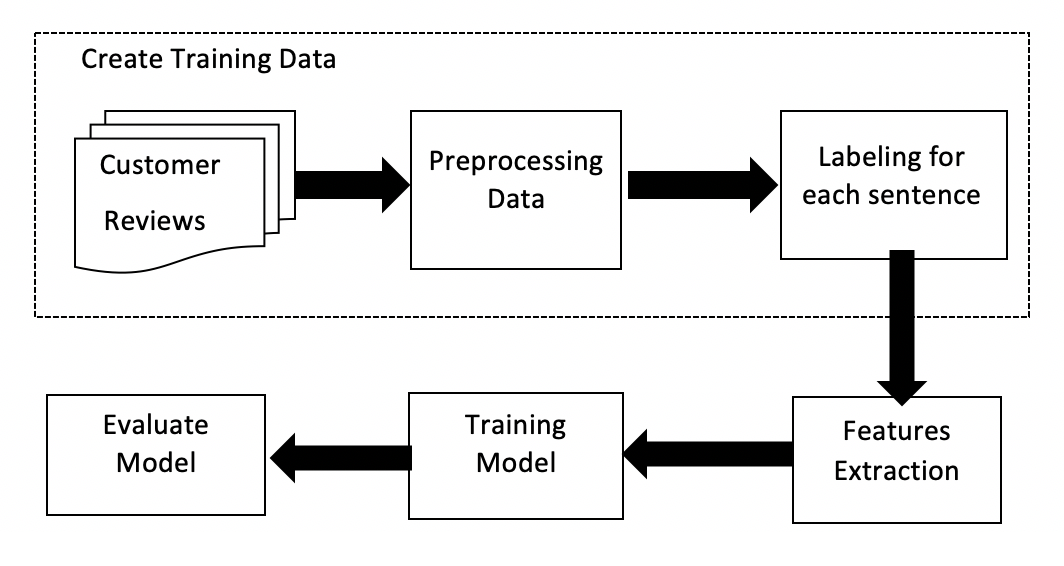
- Create Training Data: Crawling data from foody.vn, the biggest social website in the culinary field in Vietnam. Then, I will pre-processing the data and manually labeling for each sentence.
- Features extraction: The input of the model needs to be scalar values or scalar matrix values. However, the input usually a words or a sentences. Therefore, you must to convert each word in the sentence into vector, this processing step called text extraction feature. In this article, I will present two ways to extract features: Bag of Words (BoW) and Term Frequency - Inverse Document Frequency (TF-IDF).
- Training model: Using various supervised machine learning algorithms such as Naïve Bayes, Support Vector Machine or Random Forest combined with the text feature extraction methods mentioned above to training the model. After that, I will evaluate the model to calculate the accuracy.
Feature Extraction methods
Bag of Word (BoW)
Bag-of-Words is a way to extract features from text to use in modeling with machine learning algorithms. This is a way to represent textual data when modeling text with machine learning algorithms. Bag-of-Words is simple, easy to understand and used very effectively in issues such as language modeling to extract features and classify documents and BoW describes the appearance of words in a document.
For Example: We have 2 documents:
- nhà_hàng này có món cá sốt cà rất là ngon ngon.
- không_gian nhà_hàng này rất là sang_chảnh.
Based on these two documents, there will be a list of words used, called "dictionaries" with 12 words as follows:
[“nhà_hàng”, “này”, “có”, “món”, “cá”, “sốt”, “cà”, “rất”, “là”, “ngon”, “không_gian”, “sang_chảnh”]
For each document will create a vector with 10 dimensions and representing the corresponding number of words that appear in that text. With the above two documents, there are two characteristic vectors:
- [1,1,1,1,1,1,1,1,1,2,0,0]
- [0,1,0,0,0,0,0,1,1,0,1,1]
Term Frequency – Inverse Document Frequency (TF-IDF)
In data mining, the term TF-IDF (term frequency - inverse document) is the most widely known statistical method for determining the importance of a word in the paragraph in a series of paragraphs. It is often used as a weight of each word, TF-IDF converts text representation form into vector space (VSM) or into sparse vectors.
TF – Term Frequency: used to estimate the frequency of words in the text. However, for each text, there are different lengths, so the number of occurrences of the word may be more. So the number of occurrences of the word will be divided by the length of the text (the total number of words in that text). 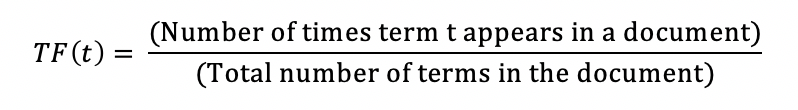
IDF-Inverse Document Frequency: used to estimate the important level of words. When Term Frequency is calculated, the words are considered equally important. However, there are some words that are commonly used but are not important to express the meaning of the paragraph, for example:
- Connection: và, nhưng, tuy nhiên, vì thế, vì vậy, …
- Prepositions: và, nhưng, tuy nhiên, vì thế, vì vậy, …
- Demonstravetive: ấy, đó, nhỉ, …
Therefore, it is necessary to reduce the importance of those words by using IDF: 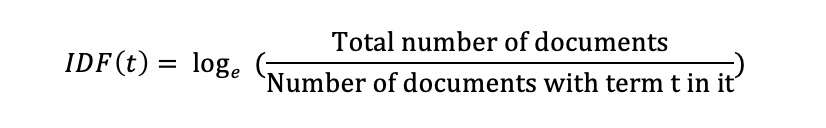
TF-IDF: 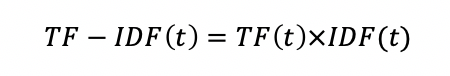
Words with a high TF-IDF value are words that appear much in this document, and appear less in other documents. This helps filter out common words and retain high-value words (keywords of that document).
Related topics:
- OCR Among Key Technology Trends to Watch in 2020
- Why Most of Digital Transformations Will Fail Without OCR?
- CIFAR10: 94% Of Accuracy By 50 Epochs With End-to-End Training
Algorithms using to extract aspect
Naïve Bayes algorithm
Naive Bayes Classification (NBC) is an algorithm based on Bayes' theorem to calculate the probability to make judgments as well as classify data based on observed and statistical data. Naive Bayes Classification is one of the most widely used algorithms in the field of machine learning.
The Bayes theorem allows the probability of a random event A when a related event B has occurred. This quantity is called conditional probability because it is derived from the given value of B or depends on that value.
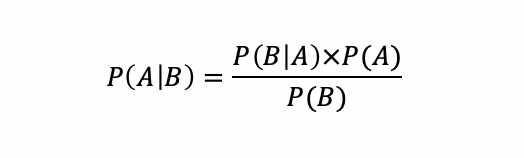
It can be seen that the probability of hypothesis A depends on the probability of hypothesis B, but in fact probability A may depend on the probability of many factors B1, B2, B3 ... Bn. So Bayes theorem can be extended by the following formula: 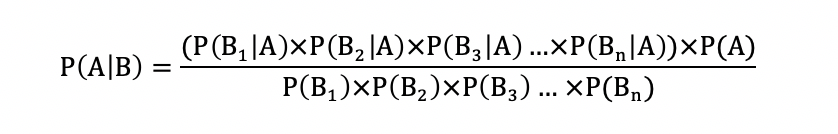
Support Vector Machine (SVM)
The idea of SVM is finding a hyperplane that can separate the dataset so that the distance from the hyperplane to the classifier is equal and largest. The SVM algorithm was originally designed to solve the binary classification problem with the following main ideas: 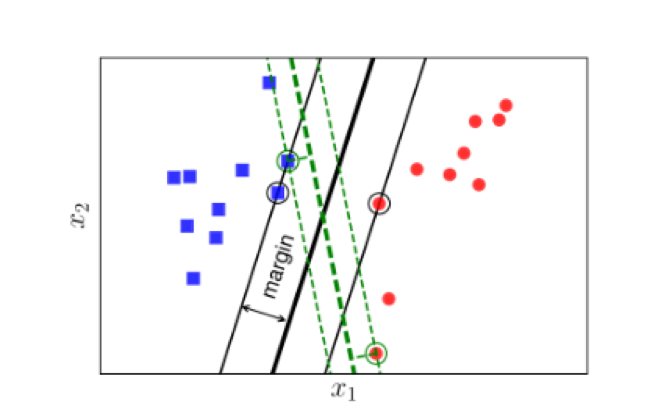
In two-dimensional space, the distance from a point with coordinates ,) to the line with equation is calculated by:
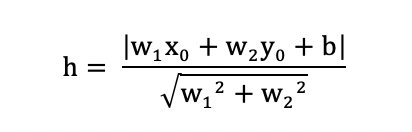
In the other hand, in two-dimensional space, the distance from a point with coordinates ,) to the line with equation is calculated by:
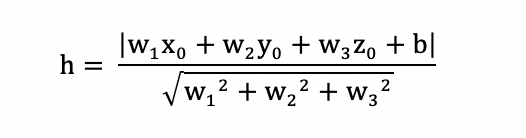
Calculate the distance on multidimensional space is more complicated than 2-dimensional space or 3-dimensinoal space and the formula of a hyperplane is . The distance is calculated by:
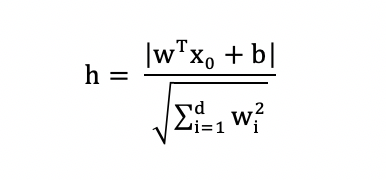
The quality of hyperplane is judged by the distance h between the two class, we try to maximize the distance h to have a better result.
Suppose that the data pairs of the training set are (x1, y1 ), (x2, y2 ),…, (x(n), y(n)) where x(i) is the input vector of a data point and y(i) is the label of the data point. Suppose the data point label has 2 values of 1 and -1. 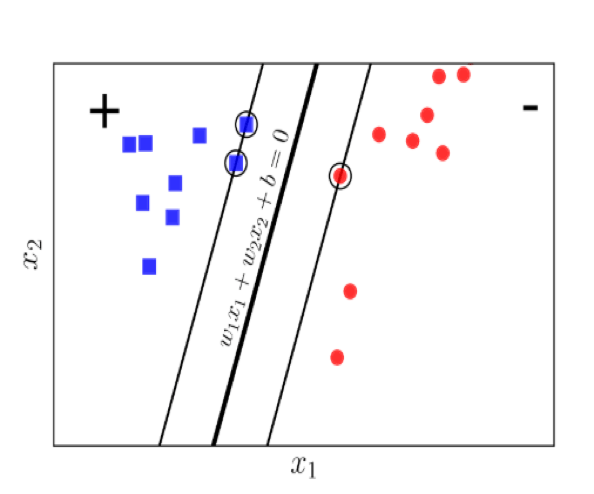
Then the distance from the point to hyperplane 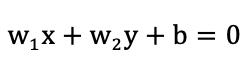 is:
is: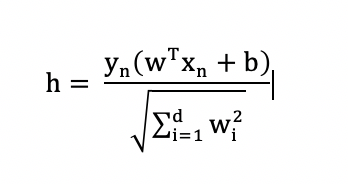
Margin is calculated as the closest distance of a point to the hyperplane: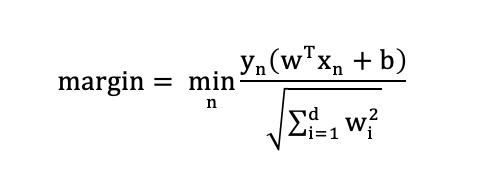
The purpose of SVM is finding w and b so that the margin reaches the maximum value: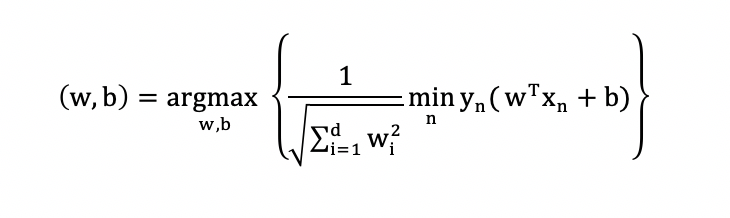
Random Forest
Random Forest is a machine learning algorithm based on assembly techniques, combining classification trees. Random Forest builds a subclass tree by randomly selecting a small group of attributes at each node of the tree to classifier trees. In addition, the sample set of each tree was also randomly selected by Bootstrap method from the original sample set. The number of classification trees in the forest is unlimited and the algorithm using the predicted results of all trees in the forest is the final result of the algorithm.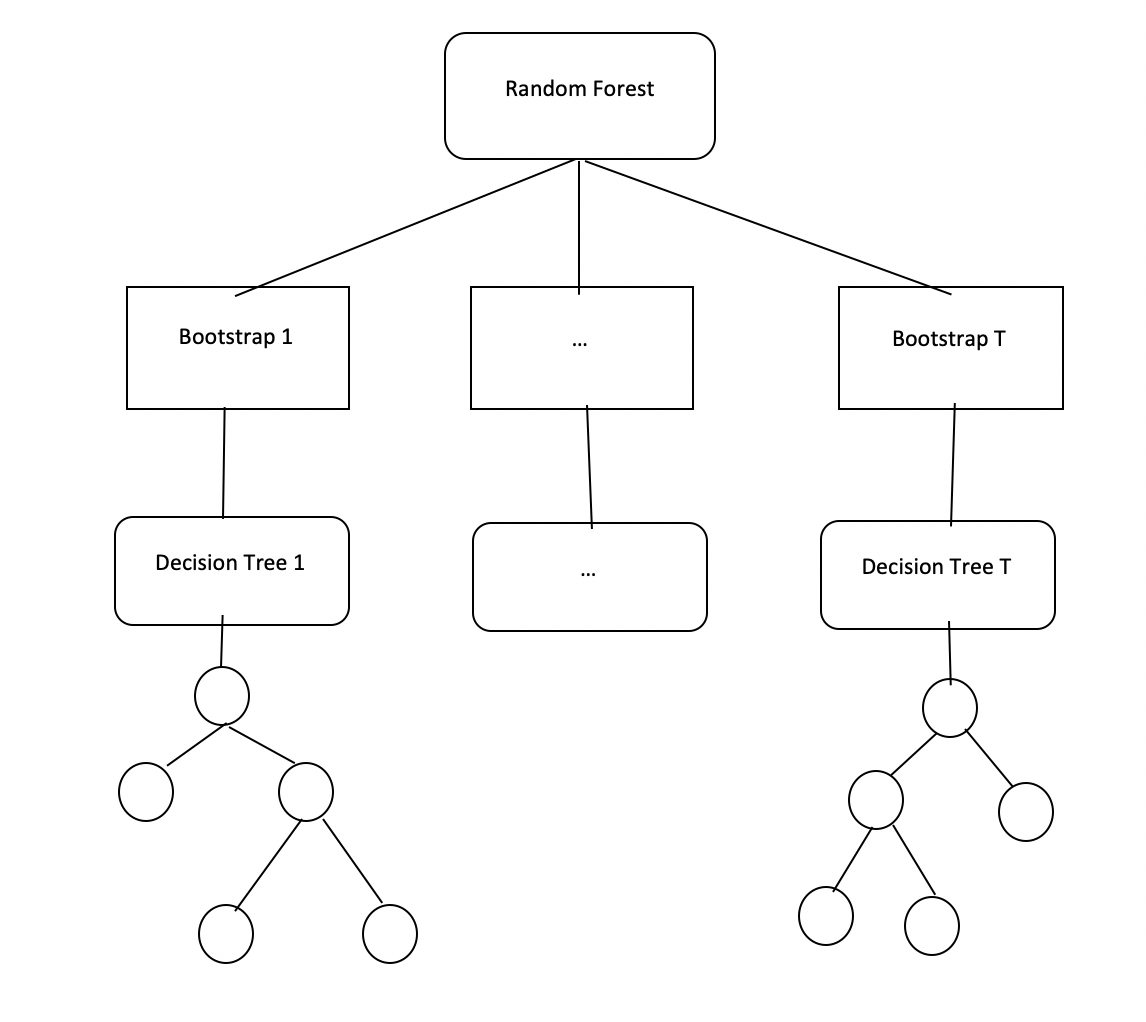
A. Training:
- Giving training dataset
- For each tree in the forest
- Building classification tree Tk with Sk, Sk get with bootstrap method from S
- At each node of the tree select the best attribute to divide the tree from the set of Fi attributes randomly selected in the attribute set F
- Each tree is built to the maximum depth (without pruning)
B. Predict:
The algorithm predicts the label for each object
- Classification: using major voting
- Regression: take the average value of all trees
Interested in other technology blogs? Click here for more!



